![]()
AWS Step Functions から別のサービスを直接統合するときに「最適化された統合 (Optimized integrations)」と「AWS SDK 統合 (AWS SDK integrations)」という選択肢がある.例えば AWS Step Functions から Amazon SageMaker Processingを実行する場合,AWS Step Functions 側で実行完了を待つ必要があることが多く,最適化された統合であれば .syncがサポートされているため,AWS Step Functions の Resourceに arn:aws:states:::sagemaker:createProcessingJob.syncと指定すれば簡単に解決できる👏
docs.aws.amazon.com
docs.aws.amazon.com
AWS CDK を使うと
実は AWS CDK では一部の最適化された統合はサポートされてなく,例えば Amazon SageMaker だと CreateHyperParameterTuningJob / CreateLabelingJob / CreateProcessingJobは現状 aws_stepfunctions_tasksに実装されていなかった.
docs.aws.amazon.com
Amazon SageMaker Processing (CreateProcessingJob) に関しては issue も出ていた💡
github.com
よって,現状では AWS CDK の aws_stepfunctions_tasks.CallAwsServiceで AWS SDK 統合を使う必要があるけど,AWS SDK 統合だと別のサービスを呼び出したら終了になってしまうという課題も残る.結果的に .waitForTaskTokenを活用したり,AWS Lambda 関数を独自実装して Amazon SageMaker Processing の DescribeProcessingJob API で ProcessingJobStatusをチェックしたりという工夫が必要になってしまう💨
aws_stepfunctions.CustomStateを使う
少し前置きが長くなったけど,AWS CDK の aws_stepfunctions_tasksでサポートされてなく .syncを実現したい場合に aws_stepfunctions.CustomStateが使える❗️CustomStateを使えば Amazon States Language (ASL)のまま AWS CDK の実装に組み込める.今回は Amazon SageMaker Processing を例に検証したことをまとめておく.基本的に他のアクションでも同じように実現できるはず〜 \( 'ω')/
docs.aws.amazon.com
1. Before: aws_stepfunctions_tasks.CallAwsService
まずは aws_stepfunctions_tasks.CallAwsServiceを使って AWS Step Functions と Amazon SageMaker Processing の「AWS SDK 統合」を実装するサンプルを紹介する.AWS CDK で作るリソースは Amazon SageMaker Processing で動かすコンテナイメージを管理する Amazon ECR 関連と AWS Step Functions 関連で,あとは細かく IAM Role なども必要になってくる.ちなみに Amazon SageMaker Processing ではシンプルに hello-worldイメージを動かすため,ProcessingInputsや ProcessingOutputConfigなどの設定は省略している😃
docs.aws.amazon.com
ポイントは aws_stepfunctions_tasks.CallAwsServiceで service: 'sagemaker'と action: 'createProcessingJob'を設定しているところ.とにかく Amazon SageMaker Processing を実行するだけなら簡単.ちなみに ProcessingJobNameは重複できない仕様になっているため,AWS Step Functions の組み込み関数 States.Formatと States.UUIDを組み合わせて動的に生成するようにした👌組み込み関数便利〜
docs.aws.amazon.com
import{
Stack,
StackProps,
aws_ecr,
aws_iam,
aws_stepfunctions,
aws_stepfunctions_tasks,}from'aws-cdk-lib'import * as ecrdeploy from'cdk-ecr-deployment'import{ Construct }from'constructs'exportclass SandboxCdkSageMakerProcessingStack extends Stack {constructor(scope: Construct, id: string, props?: StackProps){super(scope, id, props)const repository =new aws_ecr.Repository(this,'HelloWorldRepository',{
repositoryName: 'hello-world',})new ecrdeploy.ECRDeployment(this,'HelloWorldRepositoryDeployment',{
src: new ecrdeploy.DockerImageName('hello-world'),
dest: new ecrdeploy.DockerImageName(repository.repositoryUriForTag('latest')),})const sageMakerRole =new aws_iam.Role(this,'SageMakerRole',{
roleName: 'sandbox-sagemaker-role',
assumedBy: new aws_iam.ServicePrincipal('sagemaker.amazonaws.com')})
repository.grantPull(sageMakerRole)const helloWorldProcessingJob =new aws_stepfunctions_tasks.CallAwsService(this,'HelloWorldProcessingJob',{
service: 'sagemaker',
action: 'createProcessingJob',
parameters: {'ProcessingJobName.$': `States.Format('hello-world-{}', States.UUID())`,'RoleArn': sageMakerRole.roleArn,'ProcessingResources': {'ClusterConfig': {'InstanceCount': 1,'InstanceType': 'ml.t3.medium','VolumeSizeInGB': 1,}},'AppSpecification': {'ImageUri': '000000000000.dkr.ecr.ap-northeast-1.amazonaws.com/hello-world'},'StoppingCondition': {'MaxRuntimeInSeconds': 600}},
iamResources: ['*'],
additionalIamStatements: [new aws_iam.PolicyStatement({
actions: ['iam:PassRole'],
resources: ['*'],})]})new aws_stepfunctions.StateMachine(this,'SandboxStateMachine',{
stateMachineName: 'sandbox',
definitionBody: aws_stepfunctions.DefinitionBody.fromChainable(helloWorldProcessingJob),})}}AWS CDK をデプロイして AWS Step Functions を実行すると,AWS Step Functions はすぐに終了して Amazon SageMaker Processing は裏で動いていた👀
![]()
2. After: aws_stepfunctions.CustomState
今度は aws_stepfunctions.CustomStateを使って AWS Step Functions と Amazon SageMaker Processing の「最適化された統合」を実装するサンプルを紹介する.
実装は大きく変化せず,大きく2つのポイントがある.まず1つ目は aws_stepfunctions.CustomStateで Type: 'Task'と Resource: 'arn:aws:states:::sagemaker:createProcessingJob.sync'を設定しているところ.Amazon States Language (ASL)として表現できるため,Amazon SageMaker Processing を .syncで実行できる.ちなみに AWS SDK 統合だと arn:aws:states:::aws-sdk:sagemaker:createProcessingJobという ARN になる💡
2つ目は AWS Step Functions に設定した IAM Role に別途ポリシーを追加する必要があるところ.aws_stepfunctions_tasks.CallAwsServiceだと iamResources / iamAction / additionalIamStatementsあたりを設定すれば自動的にポリシーが追加される仕組みになっている.ちなみに今回の例はポリシーを少し雑に設定しているため,最小権限の原則に沿って狭めてもらえると良いかと🙏
import{
Stack,
StackProps,
aws_ecr,
aws_iam,
aws_stepfunctions,}from'aws-cdk-lib'import * as ecrdeploy from'cdk-ecr-deployment'import{ Construct }from'constructs'exportclass SandboxCdkSageMakerProcessingStack extends Stack {constructor(scope: Construct, id: string, props?: StackProps){super(scope, id, props)const repository =new aws_ecr.Repository(this,'HelloWorldRepository',{
repositoryName: 'hello-world',})new ecrdeploy.ECRDeployment(this,'HelloWorldRepositoryDeployment',{
src: new ecrdeploy.DockerImageName('hello-world'),
dest: new ecrdeploy.DockerImageName(repository.repositoryUriForTag('latest')),})const sageMakerRole =new aws_iam.Role(this,'SageMakerRole',{
roleName: 'sandbox-sagemaker-role',
assumedBy: new aws_iam.ServicePrincipal('sagemaker.amazonaws.com')})
repository.grantPull(sageMakerRole)const helloWorldProcessingJob =new aws_stepfunctions.CustomState(this,'HelloWorldProcessingJobCustom',{
stateJson: {
Type: 'Task',
Resource: 'arn:aws:states:::sagemaker:createProcessingJob.sync',
Parameters: {'ProcessingJobName.$': `States.Format('hello-world-{}', States.UUID())`,'RoleArn': sageMakerRole.roleArn,'ProcessingResources': {'ClusterConfig': {'InstanceCount': 1,'InstanceType': 'ml.t3.medium','VolumeSizeInGB': 1,}},'AppSpecification': {'ImageUri': '000000000000.dkr.ecr.ap-northeast-1.amazonaws.com/hello-world'},'StoppingCondition': {'MaxRuntimeInSeconds': 600}},}})new aws_stepfunctions.StateMachine(this,'SandboxStateMachine',{
stateMachineName: 'sandbox',
definitionBody: aws_stepfunctions.DefinitionBody.fromChainable(helloWorldProcessingJob),}).addToRolePolicy(new aws_iam.PolicyStatement({
actions: ['events:DescribeRule','events:PutRule','events:PutTargets','iam:PassRole','sagemaker:AddTags','sagemaker:CreateProcessingJob',],
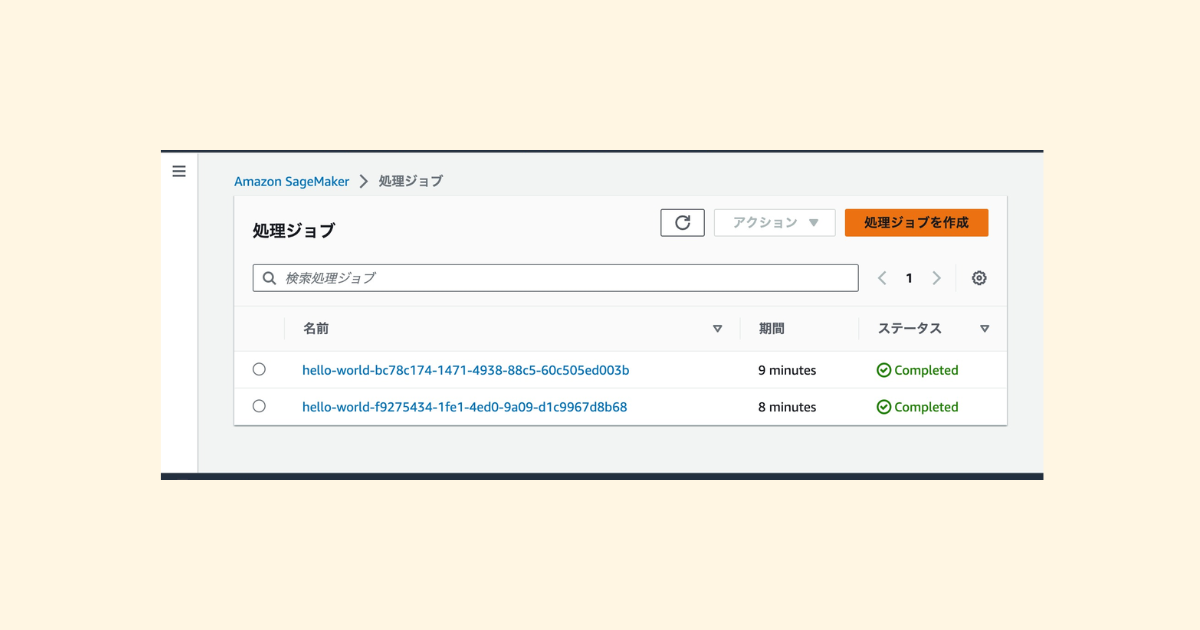
resources: ['*'],}))}}AWS CDK をデプロイして AWS Step Functions を実行すると,今度は Amazon SageMaker Processing の実行完了まで待てるようになった❗️やったー👏
![]()
Amazon SageMaker Processing Job を2回実行したログも載せておく📝
![]()




























")





")